Supercharged Agents: World Sims, Mechanistic Interpretability and Machine Societies
In this blog
What's inside
This article will help you break out of the popular view of large language models (LLMs) as chatbots.
By developing a holistic sense for what LLMs truly are, you'll be better able to reason about the nature of commercialized LLM inference products and ultimately, about AI adoption in the enterprise.
The terminology and concepts in this article will also help you have productive conversations with ML practitioners.
Introduction & backstory
We've all been exposed to LLMs as chatbots. What if I were to tell you that LLMs are not chatbots at heart? Not only are LLMs employed as chatbots, but they are also the key building blocks of agentic systems.
As part of agentic systems, LLMs:
- interpret human intent
- reason about the next steps toward a goal
- direct tool use
- understand multi-modal unstructured inputs
Yet, they are also not turn-by-turn reasoners at heart.
As LLMs proliferate in agentic networks, there are naturally more and more cases where LLMs interact directly with each other.
Machine societies
Indeed, in July 2024, I wrote a personal blog titled "The Rise of Machine Society," positing that we were on the verge of seeing unmediated (and potentially unconstrained) machine-to-machine interactions that would give rise to elements analogous to those we find in societies.
If you find that far-fetched, consider Phase 3 of MIT's Project NANDA: "Pioneering the Future of Agentic Web," titled "Society of Agents." Clearly, I am not alone in this thought process.
What are LLMs, really?
Many deployed LLMs are derived from the same or similar base models. These base models involve "post-training" steps that tune them to perform well at chatbot and instruction-following tasks.
NOTE: I use the term "post-training" as a shorthand for all of the steps involved in readying a pre-trained model for high success rates — in particular, end tasks, such as agentic, instruction-following or chatbot behaviors.
Instruction-tuned LLMs have been recruited into many roles: Some deliver content summaries, some drive agentic behaviors, and others interpret sentiment. We find them deployed in varying sizes with varying expectations about their performance and capabilities.
Yet, their true nature (derived from those base pre-trained models) is mysterious and generally misunderstood. Let's dive in….
LLMs: The friendly Shoggoth with a smiley face
The chatbot LLMs you're used to dealing with are initially trained purely as next-token-prediction models. By now, you've probably heard that fact many times. Behind that statement's apparent simplicity lies significant opportunities to tailor LLMs for surprisingly diverse tasks.
That's because during the "pre-training" process, the largest, newest, most capable (frontier) models ingest the entirety of digitized human knowledge and artifacts. Nothing about that initial training process focuses them to engage in conversational turn-by-turn interactions.
Therefore, it's reasonable to ask what their "next token prediction" capabilities are all about: If LLMs are not chatbots, then what are they?
To start answering that question, let's time-travel to 2022, when @TetraspaceWest answered by saying that LLMs are a "Shoggoth with [a] Smiley Face," posting the image on the left, below, to describe what was then GPT-3 (source, source).
The steps on the left side of the process diagram (pre-training) yield the "Shoggoth" pictured on the far left. Without the "RLHF" (post-training) steps in the box on the right side of the diagram, we don't end up with a chatbot-ready LLM.
It's reinforcement Learning with Human Feedback (RLHF) that puts that friendly face on the Shoggoth. The result is a model that can act as a friendly chatbot (too friendly, sometimes).
On the other hand, the Shoggoth that enters those post-training steps is something a bit more alien to humans: It's a world sim. In the rest of this article, we explore what that means and how we've come to that understanding.
If you want to learn more about what goes into creating a frontier model, The Llama 3 Herd of Models paper is a readable and very eye-opening overview. A "frontier model" refers to a model at the leading edge of performance and capability metrics, typically the largest, most difficult and most expensive models to create.
Model dissection
Model builders know the structure of an LLM. In fact, GPTs are relatively homogeneous, composed of many structurally identical computational blocks organized into layers, as pictured below.
Each block represents a set of deterministic vector-based computations applying that block's learned parameters to the inputs entering that block. Its outputs are fed into the following block (there's a quick review of vector concepts at the end of this article).
The process used to determine each block's parameters (also called weights) is called "training." Training utilizes techniques known collectively as "machine learning" or "statistical learning." If you've ever wondered why statistics are at the core of machine learning, take a look at this short video.
The training process uses statistical math to slowly determine the parameters that cause all of those equations in the overall model to probabilistically approximate the whole of human knowledge, given a prefix.
In a nutshell, this is tantamount to LLMs being text-based world sims. But how can we find evidence for this idea?
It's all the same in there
The observation offered above, that the model's structure is homogeneous, is important.
A consequence is that there isn't anything unique we can point to, within that structure, as the single source of all their wonderful capabilities. The introduction of "attention layers" in transformers (famously, in Attention Is All You Need) caused a step change in language models' capabilities. This fact, ablation studies, where researchers remove something about a model to study what results, point to attention layers as a key architectural element.
Again, though, this leaves us without a fine-grained understanding of the mechanisms that make LLMs so capable. Unfortunately, for anything but relatively simple model structures trained on relatively small datasets, the resulting weights are not directly interpretable.
The Kimi K2 open-weight model has over 1 trillion parameters (1T). Unlike closed-weight models like ChatGPT, anyone can download those weights. Once in hand, that's a very large pile of numbers to make sense of.
In the next section, you'll learn about some of the tools available for understanding those weights and their effects.
Mechanistic interpretability
The field of "mechanistic interpretability" studies how the astonishing capabilities of LLMs emerge from model weights. Understanding some of the key learning from mechanistic interpretability studies can help you build a better intuition about what's possible in applied LLM-based AI, including what's reasonable to expect from AI safety and guardrails.
Mechanistic interpretability: Definitions
A few definitions are helpful to understanding the content below.
- "Activations" are the results of the mathematical operations within and around each block in the model, given the inputs (versus weights or parameters, which are fixed once the model is trained). Picture activations as the values that flow through the model as the model runner "runs" (performs inference).
- The "residual stream" is a flow of activations through the model, a kind of vector "running total" of layer outputs. This "forward pass" through the model is also called inference. Layers read from and write to (often by simple addition) the residual stream. In the diagram above, it's those long arrows on the right, that feed into the (+) blocks.
- Although LLM's are "next token predictors," an LLM model does not predict a single token result per inference pass. Instead, during each pass, LLMs generate a distribution over the entire vocabulary expressed as individual probabilities (logits) on each token in the vocabulary. Then, the model runner selects (samples) from that distribution, picking a particular output token based on those logits. Temperature, top-k, and other settings can be used to modify how the runner performs the sampling. It is possible to set an LLM running such that given a set of logits, it will always pick an output from those logits deterministically (zero temperature, top-1, etc). Thus, LLMs can be deterministic.
- The functional blocks of an LLM architecture perform vector-based math. A vector is essentially a list of numbers, usually written down as a column. The length of that list is the vector's dimensionality. One interpretation of an n-dimensional vector is as a coordinate in an n-dimensional space. For example, the picture below shows a 2-dimensional vector a with components a1 and a2. These can be interpreted as coordinates of a point on the plane (a1,a2), or as the direction created by pointing from the origin to that coordinate. Vectors create a "vector space" composed of all points that any given vector can point to.
- The hidden size (d_model) of an LLM defines the dimensionality of the vectors used in its computations. Typical frontier models utilize a 4k-13k hidden size. These vectors are therefore very high dimensional.
- In 2 dimensions, you can intuit that picking any two vectors will most likely result in an angle between them that is not a right angle (their dot product will be non-zero). At higher dimensions, it's the opposite: Any two randomly selected vectors are very likely to be orthogonal to each other. The space is likely to be sparse. Keep this in mind as you read about the linear representation hypothesis (below).
- Vectors running inside a model are sometimes called embeddings, and operate within the latent space of the model.
Mechanistic interpretability: Useful tools & key learnings
With those definitions in mind, let's now explore some of the tools and learnings from mechanistic interpretability.
- Poking & Prodding
More formally called "activation patching" or "causal tracing," you run a clean and then a corrupted inference/forward pass. Swapping activations for specific layers/heads/positions between the clean and corrupted passes, and continuing the pass from that point, tests whether the swap changes the outputs. If so, the particular activations that got swapped indicate a causal link between the affected part of the model and the outputs.
See: Causal Patching - Logit Lens → Tuned Lens (layer-by-layer decoding)
The Logit Lens maps intermediate residual states directly to vocabulary logits; and the Tuned Lens learns small "translators," spotting when/where the model "knows" an answer.
See: Tuned Lens, Transformer Lens - Knowledge localization & editing
ROME and MEMIT localize facts and shows you can edit them; subsequent work explores limits.
See: Factual Associations, MEMIT - Automatic/scalable circuit discovery
Methods like ACDC (Automatic Circuit Discovery) and Path Patching/Information Flow Routes automate finding subgraphs that implement a behavior.
See: Automated Circuit Discovery - Sparse Autoencoders (SAEs) on activations
Small models trained on residual-stream activations can extract interpretable features. Recent work extracted millions of features from Claude 3 Sonnet; and open-source toolchains have emerged.
See: Transformer Circuits, SAELens, Neuronpedia - Foundational representation results
Anthropic's "toy models of superposition" formalize why features share neurons.
See: Toy Models - Many capabilities are implemented by specific, reusable "circuits"
For example, "induction head" circuits that can move information around, important to in-context learning.
See: Induction Heads , What's Needed, LLM Biology - Linear Representation Hypothesis superposition and vector directions (vs magnitudes)
That is, it looks likely that features ≈ directions, but there's evidence some features appear multi-dimensional and neurons may be polysemantic. SAEs can help distinguish monosemantic features (such as names, syntax, topics).
See: Superposition Models, ICLR Proceedings - Low-rank directions can steer high-level behaviors
Traits like sycophancy, honesty or even "evilness" can be surfaced and modulated by manipulating activation directions: Mechanistic interpretability yields control mechanisms but also guardrail escape hatches.
See: Persona Vectors, Eliciting Truthfulness - Results about truthfulness and hallucinations
OpenAI has recently released a paper on why models hallucinate, giving a more hopeful path forward than prior results which couched hallucinations as unavoidable.
See: Truthfulness, Why Models Hallucinate, Innevitable Hallucinations
Mechanistic interpretability: Takeaway
Although mechanistic interpretability research has yielded results, it's a very challenging area of research with many open problems. This review paper from January 2025 is an overview of the open problems in the area.
Why are you so large, Shoggoth?
Mechanistic interpretability gives researchers the tools needed to explore how LLMs operate. Let's now see how those tools have shaped the trajectory of LLM development over time.
Scaling laws
Empirical results showing performance tends to improve in a predictable, smooth fashion when you scale up model size, data, or compute have driven a push toward ever-larger LLMs. The resulting "scaling laws" suggest that gains fall off gradually (often as a power law), giving model designers a "roadmap" to building better models.
In this context, "performance" refers not to speed, but rather to metrics that measure how well an LLM behaves. These include cross-entropy loss, perplexity, assessment scores, and other downstream metrics. Seminal work by Hoffmann et al. in 2022 (Chinchilla) refined our understanding of scaling laws, but also showed that we may run out of data because purely increasing the size of a model without also training on a proportionately larger data set simply doesn't work.
See: Understanding Scaling Laws, Scaling in 2025, Scaling in MoEs
Chain of thought and reinforcement learning
Scaling is not the only way to improve model performance.
RLHF (Reinforcement Learning with Human Feedback) teaches pre-trained LLMs to be conversational and/or "instruction tuned," (putting the smiley face on The Shoggoth). Recent work has shown that other RL techniques can improve performance by eliciting models to output Chain of Thought (CoT) or "reasoning" tokens. The famous example proving the efficacy of RL techniques for CoT is DeepSeek R1, which I analyze in this article.
In AI, we tend to use anthropomorphized names. The Shoggoth's generated CoT tokens are the model's "probabilistic scratch pad," tipping it into higher-probability next-token predictions. Researchers have shown that CoT tokens do not necessarily correspond to correct reasoning despite improving outcomes: The Shoggoth's inner mind is alien!
RL's success at eliciting behaviors, which happens without showing the model new data of the type used during pre-training, has led some researchers to conclude that RL draws out inherent capabilities already extant in the pre-trained model.
If the model has latent behaviors that can be drawn out through RL, what else might it be capable of?
Test-time compute demands increase
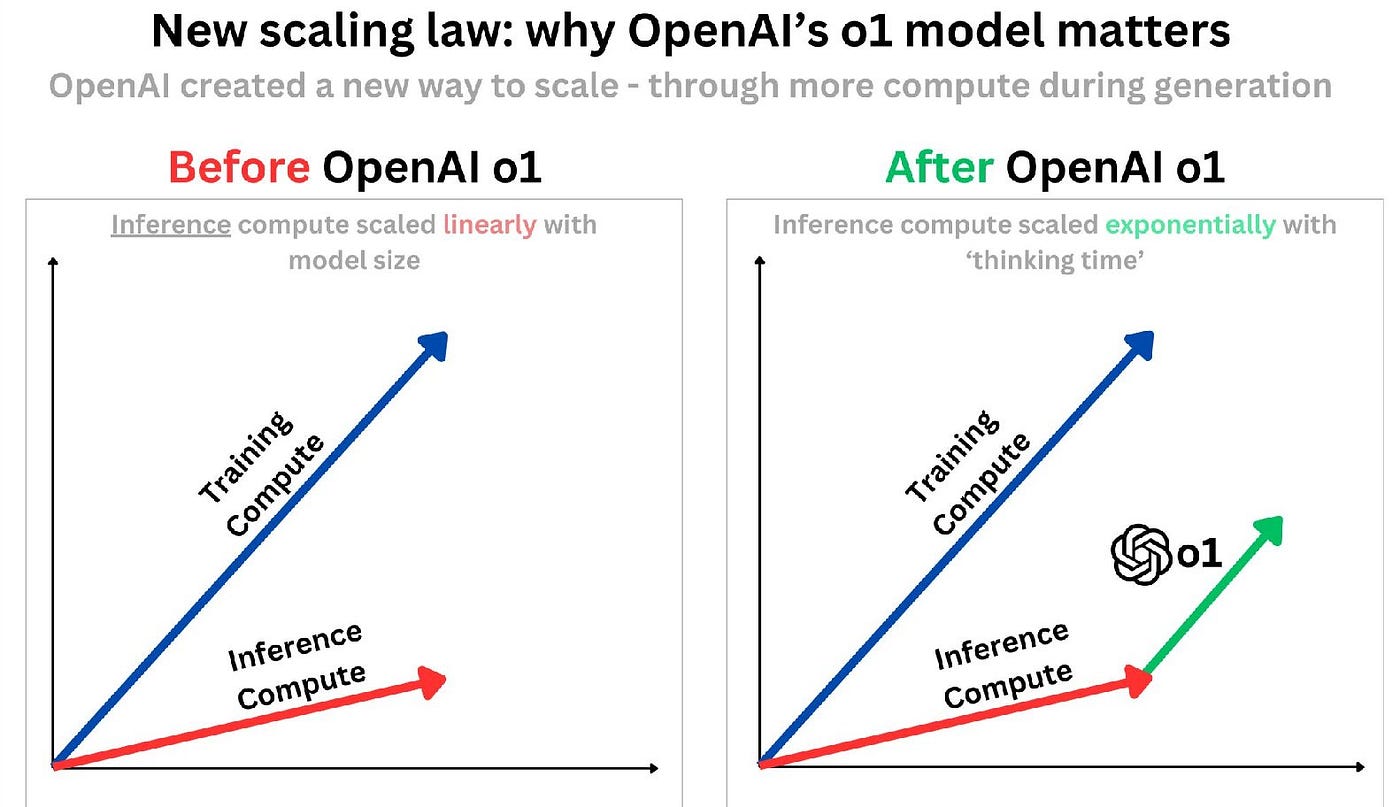
A consequence of CoT is that the number of tokens generated for any given task increases, sometimes dramatically. Whereas scaling laws have been focused on growing training-time compute, test-time (i.e., inference-time) compute is now emerging as a key factor in model performance.
This is, in some sense, unfortunate because it means that growth in total compute resources scales much more rapidly with demand (green arrow below, source).
The Platonic Representation Hypothesis (PRH)
If we were to teach a large class of students under the same curriculum, we would expect those students to come out with a similar understanding of the subject matter. In particular, we would expect the students to share a common understanding of the relationship between concepts; for example, between force and acceleration or between single-cell and multi-cellular organisms.
What about LLMs? Should we expect OpenAI's ChatGPT, trained on the same corpus of "all of human knowledge," to formulate a similar "understanding" of those concepts, as does Meta's Llama model?
As you might guess from this section's title, the answer is: Yes!
But what even does "understanding" mean for LLMs? The platonic representation hypothesis ( Huh, 2024) claims representation convergence across models/modalities. Note that, mathematically, Huh's work is compatible with the linear representation hypothesis (mentioned above) but does not rely on it; instead, it relies on the idea of pairwise similarity/distance structures derived from inner-product kernels (i.e., "understanding" means mapping input concepts to a high-dimensional geometrical representation).
More recently, those results have been extended into vision models as well (Schnaus, 2025), and there's work showing how video models develop an "intuition" for physics (Garrido, 2025).
So what?
If there is indeed a "platonic ideal" to representations learned by models, then there may be ways of translating between their latent spaces, translating embeddings from one model into embeddings of another model (Jha, 2025). This has important implications toward latent space model interoperability.
Translating embeddings between models would otherwise require a lossy and computationally expensive path from the "internal language" (embeddings) of one model, to human text/tokens, and then back to the embeddings of the target model; and such a path may only work if applied on final model outputs rather than on true latent representations (i.e., intermediate internal activations).
Validity of the PRH would also mean that universally applicable tools that operate on embeddings could be built.
The Shoggoth: A world sim
Mechanistic interpretability and the resulting hypotheses (Linear Representation, PRH) provide a foundation for a surprising conclusion about LLMs' true nature.
The Shoggoth meme boils down to the idea that the true internal nature of an LLM is alien and tangled (e.g., utilizing inscrutable polysemantic superpositioned latent space embeddings). The alien Shoggoth predicts next tokens based on a prefix without caring to fit those next tokens into a comfortable conversational straight-jacket.
RL then allows us to mold those output tokens to fit a particular mold, such as that of an agent capable of completing specific types of tasks.
Agents in the Matrix
One hypothesis is that LLMs are, in fact, simulating plausible continuations where their hidden state tracks a compact state of the world/story, supporting coherent rollouts from some given starting point. The generated tokens predict the likely result of a given prefix: If A, then probably B.
Give a pre-trained LLM a scenario, and it'll predict what should come next; that is, they are world sims (i.e., the Matrix).
The idea of LLMs as world simulators is increasingly prominent in AI research. It treats large language models not just as statistical predictors of text, but as systems that internalize and approximate a model of how the world works. This models the world's dynamics, causality, state, actions, and effects well enough to perform planning, reasoning, or prediction in novel contexts!
In this view, a model's agentic behavior is itself a simulation, running within the world sim. RL programs the LLM to run the agent simulation, versus running the chatbot simulation, or versus running the D&D dungeon master simulation.
What is a world sim?
"World model" or "world sim" is a term more common in reinforcement learning and cognitive science: It refers to an internal model of the environment's states and dynamics including how actions change things, what is causally connected to what, what hidden constraints there are, etc. When people talk about LLMs as world simulators, or "text‐based world simulators," what's typically meant is that the LLM:
- … has internalized enough knowledge from its training data to reason about aspects of the world (commonsense physics, social causality, agent goals, etc.)
- … can simulate (in text) what happens next given a state + action
- … can predict what actions are applicable in a given state or for given preconditions
- … can be used in planning tasks by using this ability to simulate outcomes
In practice, LLM world simulators are often partial and approximate. They are sometimes only valid in textual or abstract domains, and often not anchored firmly to real physical perception unless additional grounding and training is provided.
Despite these limitations, they are very powerful simulation tools — a conclusion clearly evident from the success of LLM simulations of agents!
LLM world sim literature
If you've only experienced LLMs as chatbots, it may be startling to think that they can simulate pretty much anything, not just agents. However, this is a well supported conclusion with research literature going back several years.
- Making Large Language Models into World Models.
- Can Language Models Serve as Text‐Based World Simulators?
- Evaluating World Models with LLM for Decision Making
- Measuring (a Sufficient) World Model in LLMs
- WorldLLM: Improving LLMs' world modeling
- Text2World: Benchmarking Large Language Models for Symbolic World Model Generation
- Language Models Meet World Models: Embodied Experiences Enhance Language Models
- From task structures to world models: what do LLMs know
Limitations of commercial LLMs
The world sim view has important implications for post-trained LLMs (i.e., instruction tuned/RLHF/CoT LLMs). Specifically, we should ask whether post-training is, in fact, "lobotomizing" the models by limiting the search space of their next-token predictions to those that fit the forced "Friendly Shoggoth" persona.
Anthropomorphisms aside, this would in turn imply that managed inference providers (OpenAI, Anthropic, Grok, etc.) are holding back what could be their most universally applicable models: The pre-trained bases.
These base LLMs may have exceptional latent capabilities that can be harvested via different post-training objectives. Note, however, that even already post-trained LLMs can be additionally fine-tuned and further RL trained to elicit other latent "world sim" based behaviors. However, layering like this may result in lower end-task performance.
Pre-trained LLMs are incredibly powerful tools that, after post-training, do only one of many possible personas, such as that of an instruction following agent!
Supercharged agentic networks & other applications
To supercharge agentic networks, the LLMs used to drive their behaviors should be optimized for their tasks. The world sim view of LLMs gives us a path to achieve agentic nodes that have excellent end-task performance, but are not chatbots.
Thus, a key insight from the world sim hypothesis is that fine-tuning to target ideal agentic behaviors should perhaps start with base models, rather than already instruction- or chat-tuned models.
Related commercial efforts
Fine tuning LLMs is a well-known technique, but it has so far required experienced ML practitioners. Recently, Thinking Machines Lab, a startup created by a team of ex-OpenAI researchers, including Mira Murati, has announced Tinker, an API for model fine tuning using LoRA (Low Rank Adaptation). Their bet is that fine tuning of frontier models is the next frontier in AI, which is a safe bet if the world sim hypothesis is correct.
Hidden in their documentation is a statement that seems to be a nod to the world sim hypothesis:
- We anticipate that people will want to use Tinker for RL in a few different ways:
- Creating a specialist model that's SoTA at a specific skill, which existing models haven't been trained on. In this case, you'll want to start with a post-trained model that's already strong, and then do RL on an environment you've defined…
This line of thinking is echoed in the efforts of Nous Research in their Hermes 4 model:
- Hermes 4 expands Nous Research's line of neutrally aligned and steerable models with a new group of hybrid reasoners. Like all of our models, these are designed to adhere to the user's needs and system prompts…
Further evidence comes from the world of coding models, where it's clear that non-instruction-tuned models offer a better starting point. See CodeLlama and Mistral.
Applications for LLMs as simulators
Instruction-tuned LLMs are the core of today's complex agentic networks, performing the tasks in the bullet list at the top of this article. The world sim view of a pre-trained LLM indicates those agents are in fact themselves simulations running within a much more globally capable simulator of the world.
Put another way, the agents emerging from LLMs are a latent capability (drawn out by the post-training process) of the overall pre-trained LLM: The LLM is simulating an agent! What else could pre-trained LLMs be coaxed into simulating?
Some curated ideas for LLMs as simulators:
- Policy & market sandboxes
Prototype interventions (tax schemes, misinformation countermeasures, pricing changes) using population-scale agent sims (e.g., OASIS for platforms; EconAgent for macro).
See: OASIS, EconAgent - Urban & operations planning
Stress-tests of zoning, transit, or emergency plans with city-scale agents.
See: OpenCity,CitySim - Simulation-to-real for agents/robots
Use LLM based planning and explicit symbolic models to train agents and robots.
See: WorldCoder, SayCan - Training data & evaluation harness
Use multi-agent role-play (CAMEL) to generate edge cases or red-team safety.
See: CAMEL - Education & rehearsal spaces
"Generative agents" as tutors, negotiation partners, or stakeholder role-players
See: Generative Agents - Improved code generation
Line-by-line execution-guided generation that injects runtime signals during decoding.
See: EG-CFG - Simulator style role fidelity in agentic networks
World-sim framing (plan → act → observe → revise) underpins classic agent methods yielding with stronger base models yielding better plans and self-critiques.
See: ReAct, Reflexion, Tree-of-Thoughts
A side note on structured outputs
Building successful agentic networks often involves ensuring that model outputs are structured (e.g., json), so that the outputs can be processed by procedural code as well as agentic LLMs. This is particularly important for tool use requests emitted by agents, or for outputs that are used as inputs to prompt template renders. This recent paper may be of interest: SLOT.
Conclusion
"Machine societies of alien Shoggoths, interacting with each other using self-taught inscrutable latent space embeddings" sounds like the title of a 1950s science fiction novella, but as you've learned above, science fiction may predict reality.
I hope this article will inspire you to dig deeper into the foundations of today's most capable LLMs.