Workload Management & Orchestration Series: Slurm Workload Manager
In this blog
If you've worked in high-performance computing (HPC), machine learning operations (MLOps), data science, data management or any scenario that involves vending shared compute resources to a user community, you've probably used various workload management and/or orchestration tools. This series explores some of these at a high level to help you understand each tool's characteristics beyond the marketing hype.
Slurm Workload Manager: Scheduling for HPC environments
Slurm Workload Manager is a highly scalable, open-source job scheduling system designed for high-performance computing (HPC) environments that has been widely adopted at large-scale sites such as the U.S. National Laboratories, NOAA and major academic supercomputing centers. It operates with a simple architecture that scales to thousands of nodes and hundreds of thousands of cores.
Core capabilities
Architecture
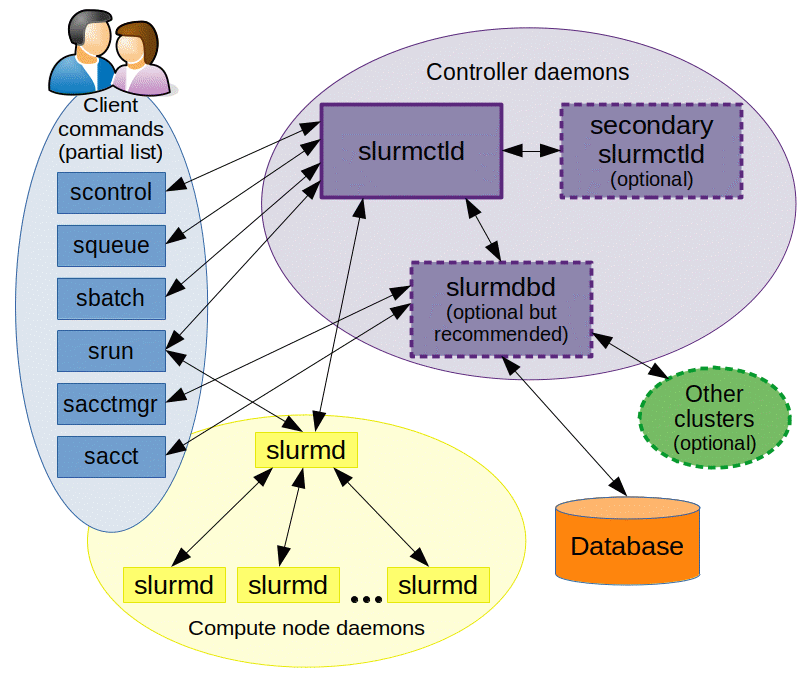
Slurm is designed around a lightweight, highly modular daemon architecture centered on two daemons called slurmctld and slurmd, respectively focused on overall cluster control and single node control. In this way, Slurm's architecture cleanly separates control logic from execution on compute nodes.
The slurmctld daemon is typically deployed onto primary and backup control plane servers for high availability, and handles scheduling decisions, job queue management, overall state tracking and control of the slurmd daemons. There is no reliance on SSH for job launch. Instead, a slurmd daemon runs on every compute node, handling low-level operations such as launching tasks, monitoring resource usage and reporting status back to slurmctld. Slurmd processes communicate via authenticated RPC over TCP sockets, offering greater control, efficiency and security compared to SSH-based systems on a designated control machine. For clusters that require job accounting or multi-site federation, the slurmdbd daemon provides a backend database interface, such as MySQL or MariaDB, storing historical usage data, user statistics, and detailed job logs for billing or audit purposes.
Plugins
Slurm's true flexibility comes from its plugin framework, which allows administrators to tailor nearly every aspect of scheduling and resource management without changing the base code, including elements like which authentication service should be used to ensure secure message exchange. Scheduling policies — such as backfill, fair-share, partition-based priorities and preemption — are implemented as interchangeable plugins that query the state maintained by slurmctld to rank and dispatch jobs.
Likewise, resource selection (e.g., node feature lists, GPU reservations), job prolog/epilog scripts, checkpoint/restart mechanisms, and authentication modules are all pluggable, enabling seamless integration with site-specific hardware or policy requirements. This design not only simplifies upgrades and customization but also allows Slurm to scale from small departmental clusters to some of the world's largest supercomputers by adding or tuning individual components rather than overhauling the entire system.
Job model
Compute nodes are grouped into partitions (akin to job queues), and jobs are submitted to these partitions for scheduling and execution. Slurm supports advanced features like job arrays, resource limits, topology-aware scheduling, preemption and multi-factor job prioritization, making it particularly effective in tightly coupled parallel computing environments such as those using MPI.
Jobs in Slurm are defined using a batch script (submitted via sbatch) or as interactive sessions (via srun or salloc). Job scripts can be written in any scripting language so long as they start with a valid "shebang" reference to the script interpreter. The batch script can be annotated with Slurm directives (#SBATCH) that declare the job's resource requirements and metadata, but some of these can also be specified on the command line when launching the job. These directives specify the number of nodes, tasks per node, CPU and memory limits, job timeouts, partition (queue), job name, output files and other scheduling parameters. Here is an example batch script:
#!/bin/bash
#SBATCH --job-name=simulation
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=16
#SBATCH --time=02:00:00
#SBATCH --partition=compute
#SBATCH --output=sim_%j.out
srun ./my_simulationWhen submitted, the job is scheduled according to cluster policies. Each submitted job is tracked with a unique job ID and may include multiple job steps — units of execution managed by srun — which can launch parallel tasks across the allocated resources. Slurm also supports job arrays, allowing users to submit a large number of similar jobs with indexed variations, useful for hyperparameter sweeps or ensemble simulations.
Command line & REST
Slurm is controlled on the command line. You can find a summary of all of slurm's commands here, and if you are moving over from similar workload managers such as PBS/Torque, LSF, SGE, or Loadlever you may find this useful. Slurm also provides a RESTful interface, documented here.
High efficiency
Bare metal
In HPC contexts, minimizing resource utilization can be paramount to maximizing overall cluster performance. Slurm excels in this regard because jobs can run directly on bare metal if so desired. On the other hand, nothing prevents Slurm from starting containerized jobs either! Because of this minimal approach, properly configuring Slurm clusters requires planning and often involves defining compute node OS images that ensure all of the necessary tooling and executables are included and accessible from a consistent directory structure. Such concerns may impose requirements on the cluster's distributed storage infrastructure as an underlying mechanism to provide a homogeneous compute environment for jobs.
For example, Slurm doesn't inspect the script contents beyond the shebang and SBATCH directives. Instead, it passes the script to the specified interpreter for execution. This means the scripting environment must be properly configured — e.g., Python modules must be importable via environment variables set by module commands (when using the modules configuration management system, common in HPC environments), or must be explicitly imported in the script. As mentioned above, it is common to set up clusters such that a shared filesystem exists between the compute nodes (CNs), and this filesystem is frequently extended to front-end nodes (FENs) so that users can easily develop and debug job scripts.
While jobs are running, the slurmd daemon on each node remains active and uses a small amount of system resources to monitor job health, enforce resource limits (CPU, memory, GPU, etc.), and manage process hierarchies (via cgroups or cpusets). However, its overhead is minimal and designed to be non-intrusive relative to job execution. Slurm's architecture is explicitly optimized to minimize control plane bottlenecks and scale to hundreds of thousands of cores. Job accounting, if enabled, may introduce some I/O overhead during job completion, but this is typically offloaded to the SlurmDBD component running on a separate node.
Topology awareness
Quoting directly from Slurm's documentation: "Slurm can be configured to support topology-aware resource allocation to optimize job performance. Slurm supports several modes of operation, one to optimize performance on systems with a three-dimensional torus interconnect and another for a hierarchical interconnect. The hierarchical mode of operation supports both fat-tree or dragonfly networks, using slightly different algorithms… [On systems that have a three-dimensional interconnect topology Slurm allocates resources] using a Hilbert curve to map the nodes from a three-dimensional space into a one-dimensional space. Slurm's native best-fit algorithm is thus able to achieve a high degree of locality for jobs."
Support for containers
Slurm has minimal built-in support for containers, workflows or ML-specific abstractions out of the box, but it integrates with Apptainer (formerly Singularity, more on this below) and can be extended with wrappers or hooks to accommodate containerized and hybrid workloads. In environments where Slurm is used alongside cloud-native or AI-oriented tooling, it often acts as the resource manager underneath higher-level workflow orchestrators.
What is Apptainer?
Apptainer is a container runtime designed specifically for HPC and multi-user cluster environments. It allows users to package their application code, libraries and dependencies into portable container images, similar to Docker, but with a security and execution model tailored for unprivileged users on shared systems, minimizing performance impacts. For those of you familiar with Docker, you can think of an Apptainer container as a container that sets up resource namespaces and isolations on a per-job basis using some of the same kernel facilities as Docker, in combination with bind-mounts and other techniques depending on the resource. The job's context is set up by an SUID binary that drops back to user privileges once the job is configured.
It integrates naturally with Slurm because it allows users to execute containers without requiring root privileges. A typical Slurm job can launch a containerized workload by wrapping the execution command in an Apptainer invocation, within which srun may be used if appropriate (e.g., for OpenMPI jobs).
Apptainer supports MPI workloads, GPU passthrough (via NVIDIA container hooks), and access to the host filesystem and interconnects, making it suitable for running both tightly coupled parallel codes and self-contained ML workloads. It preserves user identity inside the container, aligns with HPC file system semantics, and allows read-only or writable image modes. Because it runs in user space, it can be invoked inside Slurm jobs with minimal cluster configuration, enabling reproducible, portable workflows even when porting the job to a different cluster in a different organization.
Unique advantages
Slurm is a mainstay in scientific computing for good reason, providing some unique advantages:
- Unmatched scalability and efficiency
In contrast to Slurm, platforms built on container-orchestration layers often incur extra resource and networking overhead, especially at a very large scale. - Rich, plugin-driven scheduling policies
Other ML-focused systems often suffer from limited scheduling flexibility defined by the vendor and often tied to GPU-oriented quotas, leaving little room for site-specific optimizations around MPI, InfiniBand topology or node heterogeneity. - Deep integration with MPI and high-speed interconnects
Slurm's native support for MPI process launch (via srun), topology-aware placement and allocation of high-bandwidth fabrics makes it the de facto choice for workloads consisting of thousands of tightly coupled individual units of work. Run:AI and Ray excel at container-based GPU pooling and elastic scaling of loosely coupled tasks, but lack Slurm's fine-grained controls. - Comprehensive accounting and multi-cluster federation
Through slurmdbd, Slurm can aggregate detailed historical job, user, and reservation data into a central SQL database, enabling chargeback, auditing and cross-site federation. While ClearML provides experiment tracking and some metadata logging for ML pipelines, it doesn't replace system-level accounting or support administrative features like multi-partition hierarchies and advanced QoS controls across federated clusters. - Minimal external dependencies
Slurm's only required external service is an authentication library such as Munge. In contrast, Run:AI and ClearML typically demand a full Kubernetes stack (etcd, API servers, ingress controllers) and often additional services (Redis, RabbitMQ, metadata databases), increasing operational complexity and attack surface.
Integrations
- Authentication and authorization
- Munge: The de facto lightweight secure authentication service used by Slurm daemons to verify node-to-node and client-to-server messages.
- LDAP/Active directory: Via the pam_slurm_adopt or pam_ldap modules, Slurm can map cluster users and groups to existing enterprise directory services for unified identity and access control.
- Accounting and reporting
- slurmdbd (MySQL/MariaDB/PostgreSQL): Centralizes historical job, user, reservation and QoS data for chargeback, auditing and cross-cluster federation.
- XDMoD/Grafana + Prometheus: Exporters and connectors enable real-time and historical metrics ingestion for dashboarding, anomaly detection and capacity planning.
- Container and application environments
- Singularity/Apptainer: Native integration allowing
srunandsbatchto launch containerized workloads with minimal modifications to job scripts, preserving native MPI and GPU support. - Shifter/Charliecloud: Kubernetes-style OCI image runtimes that plug into Slurm's task launch pipeline for seamless Docker image execution without requiring full Kubernetes.
- Singularity/Apptainer: Native integration allowing
- MPI and high-speed interconnects
- srun MPI Launch: Deep hooks into OpenMPI, MVAPICH, Intel MPI and others for tight coupling, rank-aware placement and optimized PMI/PMIx handshake.
- RDMA fabric topology plugins: Awareness of InfiniBand, Intel Omni-Path or NVIDIA Quantum fabrics for topology-aware node allocations and binding.
- Checkpoint/restart and job reliability
- BLCR/DMTCP: Checkpoint/restart frameworks that integrate with Slurm's job prolog/epilog hooks to transparently checkpoint long-running jobs and resume after failures.
- Burst buffers: Interfaces to Lustre, BeeGFS or vendor-specific burst-buffer layers to stage I/O in high-performance SSD pools and reduce checkpoint overhead.
- Cloud and elastic scaling
- AWS ParallelCluster/Azure CycleCloud: Orchestrators that automate the provisioning of Slurm control and compute nodes in public clouds, mapping Slurm partitions to cloud instance fleets.
- Elastic computing plugin: Enables Slurm to dynamically spin up or tear down compute nodes based on queue depth using cloud APIs (OpenStack, AWS, Azure).
- Filesystem and data distribution
- CVMFS / BeeOND: Read-only distributed file systems and on-demand burst-buffered file staging to ensure consistent, low-latency access to large software stacks or datasets.
- Lustre / GPFS Clients: Automation of mount points and QoS parameters through prolog/epilog scripts for high-throughput parallel I/O.
- Monitoring and alerting
- Slurm telemetry (slurmrestd + Ganglia/Prometheus): A REST API layer to expose Slurm metrics; combines with third-party collectors for live health dashboards and automated alerting.
- Node health check scripts: Hooks that execute custom health checks (e.g., GPU memory tests, network ping) before node admission, isolating faulty hardware automatically.
Summary
With minimal external dependencies and proven scalability, Slurm remains the scheduler of choice for scientific and enterprise HPC workloads.
Slurm is a highly scalable, open-source workload manager optimized for high-performance computing (HPC) environments. Its modular architecture features lightweight daemons, avoids SSH for job dispatch, and supports high availability, topology-aware scheduling and MPI integration, maximizing efficiency and making it ideal for tightly coupled workloads. Administrators can extend Slurm through a powerful plugin system. Slurm integrates with container runtimes like Apptainer, supports bare-metal execution, and interfaces with Lustre, BeeGFS, and burst-buffer systems for efficient I/O. It also provides detailed job accounting via slurmdbd, supports cloud bursting through AWS and Azure integrations, and exposes metrics via REST and Prometheus.