Workload Management & Orchestration Series: NVIDIA Run:ai
In this blog
NVIDIA Run:ai is a Kubernetes-native AI workload orchestration platform designed to optimize GPU utilization and streamline the deployment of machine learning (ML) and deep learning (DL) workloads. It provides dynamic resource management, intelligent scheduling and seamless scalability across hybrid and multicloud environments.
Unlike traditional HPC schedulers like Slurm, which are optimized for tightly coupled MPI workloads with designs that aim to get jobs as close to the "bare metal" as possible, NVIDIA Run:ai focuses on simplifying AI infrastructure management while maximizing GPU utilization and efficiency. Run:ai offers a modern solution for orchestrating AI and ML workloads, addressing certain limitations of traditional HPC schedulers like Slurm in these contexts.
At its core, NVIDIA Run:ai integrates with Kubernetes clusters to manage GPU resources effectively. It enables dynamic GPU allocation, pooling and partitioning, allowing multiple jobs to share GPUs efficiently. This approach ensures fair allocation in multi-tenant environments and supports features like preemption and priority-based scheduling.
NVIDIA Run:ai's architecture comprises several key components delivered via a modular design that allows it to manage AI workloads efficiently across diverse environments:
- NVIDIA Run:ai Scheduler: An AI-native scheduler that extends Kubernetes' capabilities to manage GPU resources effectively.
- Resource Manager: Handles dynamic allocation and pooling of GPU resources across workloads.
- Monitoring & Analytics: Provides real-time insights into resource utilization and job performance.
- API Gateway: Facilitates integration with external tools and services.
One of NVIDIA Run:ai's standout features is its support for dynamic GPU allocation, a feature called Dynamic GPU Fractions. This capability enables workloads to specify and consume GPU memory and compute resources by leveraging Kubernetes Request and Limit notations.
Run:ai also provides robust multi-tenant capabilities within an enterprise, allowing different teams or departments to share GPU resources securely and efficiently. Note that "multi-tenant" here refers to features that allow multiple users with a relatively high degree of mutual trust to use the Run:ai instance together. In other settings, "multi-tenancy" involves untrusted cohabitation of an infrastructure (think cloud compute providers) and involves security and segregation capabilities and associated user-interfaces that go beyond Run:ai's scope. In Run:ai, administrators can set quotas and policies to manage resource allocation across tenants, ensuring fair and efficient usage of GPU resources.
Built on Kubernetes, NVIDIA Run:ai integrates seamlessly with existing Kubernetes clusters, leveraging native tools and APIs for deployment and management. This integration simplifies the orchestration of containerized AI workloads and supports popular ML frameworks and tools, including TensorFlow, PyTorch, MLflow, and Kubeflow.
NVIDIA Run:ai has demonstrated significant improvements in resource utilization and workload throughput via its dynamic allocation of GPU resources, enabling efficient sharing. This leads to higher GPU utilization, reduced idle times and accelerated AI development cycles.
More on GPU fractionalization
Run:ai's GPU Fractions feature provides a flexible way to share GPU memory and compute resources across multiple workloads, rather than assigning full GPUs per job. Instead of submitting integer GPUs, users specify fractional GPU memory (percentage or exact size), and Run:ai dynamically partitions and enforces these allocations to create isolated "logical GPUs." Each workload runs in its own virtual memory space, ensuring strict memory caps and no crossover.
Key advantages include:
- Faster launch times: Smaller fractional requests can be scheduled quickly in otherwise fragmented clusters.
- Better GPU utilization: You can deploy more workloads per physical GPU, boosting throughput.
- Fairer resource distribution: Quota planning through fractional allocations enables administrators to parcel quotas (e.g., 0.5 GPU per researcher), while still supporting over-quota usage.
Under the hood, the Run:ai scheduler reserves an entire GPU via a "reservation" pod, then on each node, its GPU Fractions logic allocates memory slices and applies NVIDIA's time-slicing for compute sharing. This flexible setup allows any memory split from 0 to 100 percent dynamically.
Multi‑GPU fractions extend this concept: Workloads can request consistent fractions across multiple GPUs (e.g., 8×40 GB out of 80 GB on H100s), enabling shared access to the remaining capacity on each GPU.
In summary, Run:ai GPU Fractions transforms static GPU assignment into a dynamic, shareable resource pool — boosting utilization, reducing wait times and offering granular quota management.
Deployment architecture
NVIDIA Run:ai's architecture comprises two primary components (see NVIDIA Run:ai Overview):
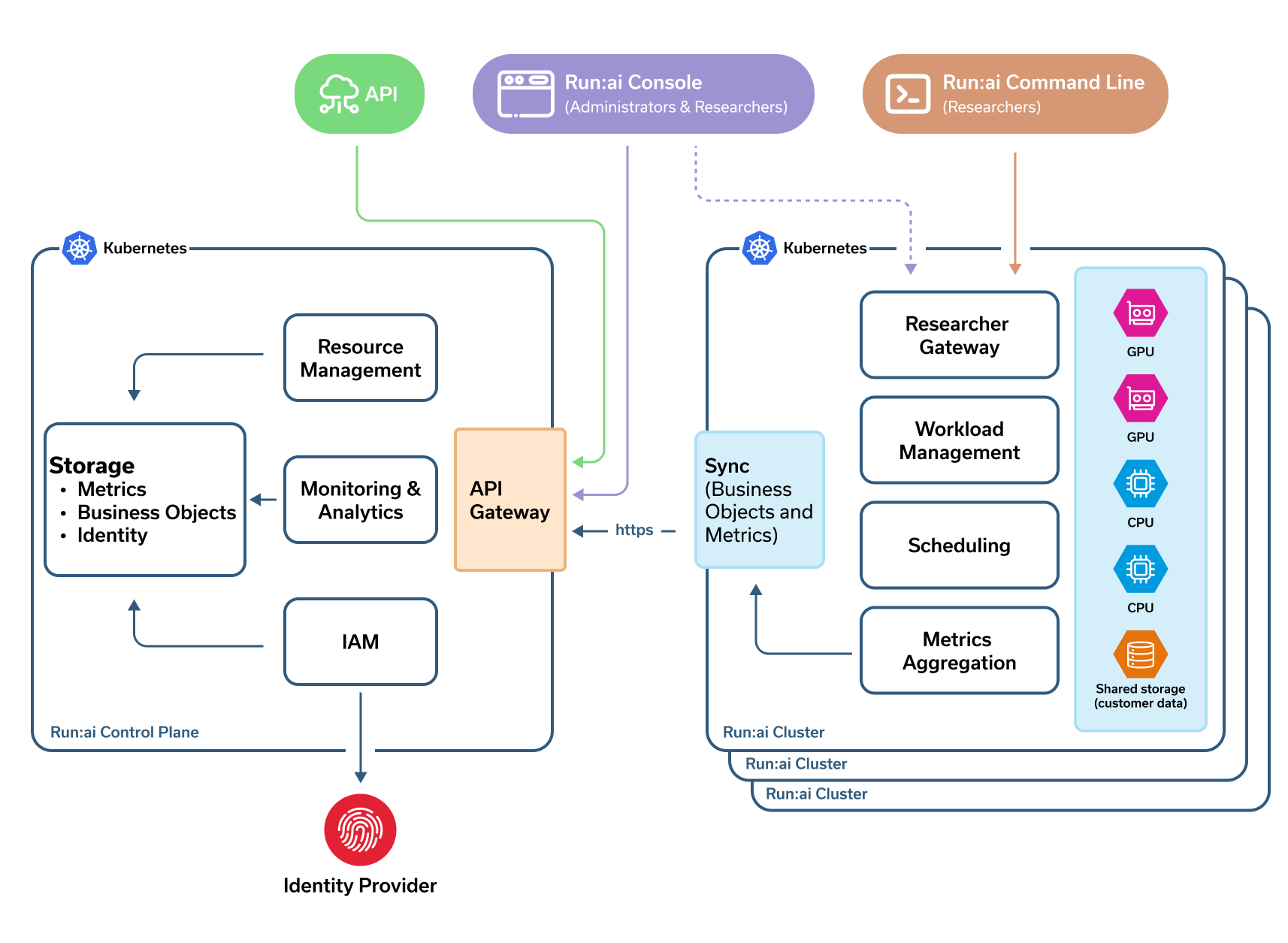
NVIDIA Run:ai Cluster: This component provides scheduling services and workload management. It includes the Run:ai Scheduler, a specialized scheduler that understands the nature of AI workloads and associated resources better than the default Kubernetes scheduler. The Run:ai cluster is installed as a Kubernetes Operator within its own namespace named runai. Workloads are executed in the context of Run:ai Projects, each mapped to a Kubernetes namespace with its own settings and access control.
NVIDIA Run:ai Control Plane: This component provides resource management, workload submission and cluster monitoring. It can be deployed as a Software as a Service (SaaS) offering or installed locally. The control plane manages multiple Run:ai clusters, allowing a single customer to oversee multiple GPU clusters across on-premises, cloud and hybrid environments from a unified interface.
Both components are installed over Kubernetes clusters, and administrators are responsible for managing these Kubernetes clusters separately from the Run:ai platform. Administrators must manage the underlying Kubernetes clusters, including tasks such as cluster provisioning, node management and ensuring high availability.
NVIDIA Run:ai does not abstract away the need for Kubernetes management; instead, it enhances Kubernetes' capabilities to better serve AI and ML workloads, and it supports various Kubernetes flavors, such as OpenShift, and cloud provider versions. Similarly, Run:ai integrates with an organization's existing security infrastructure. NVIDIA Run:ai supports multiple authentication methods to cater to diverse organizational needs:
- Single sign-on (SSO): Integrates with existing identity providers using SAML, OpenID Connect (OIDC), or OpenShift. SSO allows users to access NVIDIA Run:ai using their organizational credentials, streamlining the login process and centralizing user management.
- Secret key (for application access): Applications interacting with Run:ai APIs can authenticate using a secret key mechanism. This involves creating a client application within Run:ai, assigning appropriate roles, and using the generated secret to obtain a bearer token for API access.
- Username and password: NVIDIA Run:ai does support traditional username and password authentication, which can be useful for "break-glass" accounts.
Access controls
NVIDIA Run:ai extends Kubernetes' RBAC by introducing a more granular and scalable access control system:
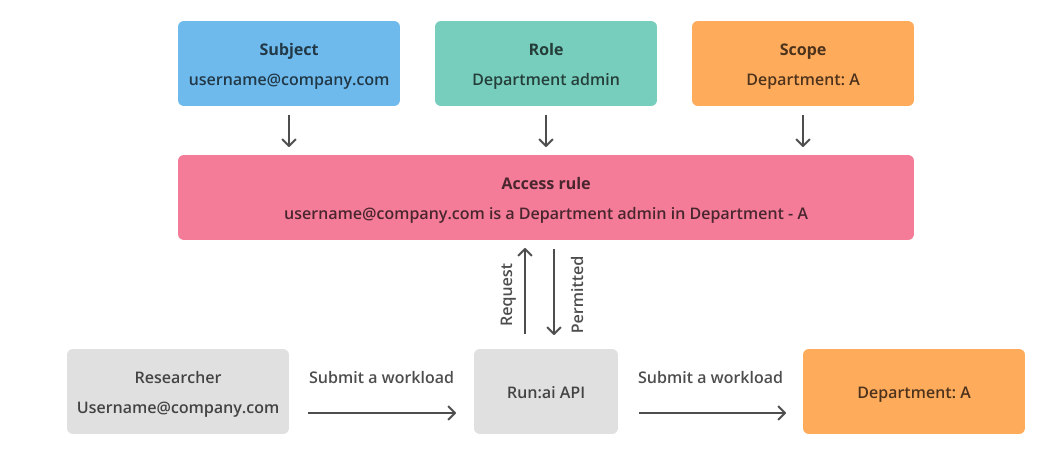
- Subjects: Entities such as users, groups or applications that require access.
- Roles: Predefined sets of permissions that determine the actions a subject can perform. Roles in Run:ai are system-defined and cannot be modified or deleted (e.g., System Administrator, Department Administrator, Research Manager, L1/L2 Researcher, Viewer).
- Scopes: Define the boundaries within which roles are effective (e.g., Project, Department, Cluster, Account).
User interface
NVIDIA Run:ai offers a unified user interface that serves both administrators and researchers, providing tools for cluster management, workload orchestration and resource monitoring. This interface is accessible via a web browser and is designed to cater to different user roles within an organizations, divided into two main sections:
- Administrator Console: Allows administrators to manage clusters, monitor resource utilization, and configure system settings. Key features include:
- Dashboard views of cluster status, GPU allocation and job queues.
- Management of users, departments, projects and applications.
- User Management: Administrators can add, modify or remove users, assign roles and define scopes through the Run:ai interface. SSO users are automatically added upon first login, while local users can be created manually.
- Application Management: For programmatic access, administrators can register applications, assign roles, and generate secrets for API authentication. This facilitates automation and integration with CI/CD pipelines.
- Access to job details for troubleshooting and support.
- Researcher Workbench: Provides researchers with tools to submit and manage their AI workloads. Features include:
- Job submission and monitoring.
- Access to job logs and resource usage statistics.
- Integration with popular AI frameworks for streamlined workflows.
The interface integrates information from both the Run:ai control plane and the underlying GPU clusters, ensuring users have a comprehensive view of their resources and workloads.
For users who prefer or require command-line interactions, NVIDIA Run:ai provides a CLI tool that enables:
- Submission and management of AI workloads.
- Monitoring of job statuses and resource utilization.
- Integration with scripting and automation tools for advanced workflows.
The CLI is designed to work seamlessly with the Run:ai control plane, providing consistent functionality across both interfaces.
NVIDIA Run:ai Included with NVIDIA Mission Control
As we move into the era of AI factories where enterprises need software-defined intelligence to manage infrastructure complexity and orchestrate workloads, NVIDIA has developed Mission Control.
AI practitioners now possess a comprehensive suite of tools to accelerate their workloads, enabling them to access necessary compute resources and seamlessly orchestrate workloads for model development, training and inference. These tools offer the flexibility to tune GPU performance for various workload types, optimizing efficiency and results. Plus, it delivers gold-standard infrastructure resiliency by automatically identifying, isolating and recovering from hardware failures, eliminating the need for manual intervention and ensuring that progress is never lost.
The NVIDIA Run:ai technology is one aspect of NVIDIA Mission Control, promoting AI lifecycle integration, resource management and orchestration. The image below provides a high-level perspective of all functional components of NVIDIA Mission Control.
Integrations
NVIDIA Run:ai integrates well with other tools in various categories, including:
- Orchestration tools
- Spark (community support)
- Kubeflow Pipelines (community support)
- Apache Airflow (community support)
- Argo Workflows (community support)
- Seldon Core/SeldonX (community support)
- Development environments
- Jupyter Notebook (supported)
- JupyterHub (community support)
- PyCharm (supported)
- VS Code (supported)
- Kubeflow Notebooks (community support)
- Distributed computing frameworks
- Ray (community support)
- Experiment tracking
- TensorBoard (supported)
- Weights & Biases (W&B) (community support)
- ClearML (community support)
- Model serving/ML lifecycle
- Triton (via Docker base image)
- MLflow (community support)
- Hugging Face (supported)
- Storage and code repositories
- Docker Registry (supported)
- S3 (supported)
- GitHub (supported)
- Training frameworks
- TensorFlow (supported)
- PyTorch (supported)
- Kubeflow MPI (supported)
- XGBoost (supported)
- Cost optimization
- Karpenter (supported)
When NVIDIA Run:ai makes sense
Here are key points of interest when NVIDIA Run:ai may make sense to utilize compared to other competitors:
- Maximizing GPU utilization: This is arguably NVIDIA Run:ai's most significant value proposition. Data science teams often face bottlenecks due to limited access to GPUs or inefficient sharing. Competitors may offer basic resource allocation in Kubernetes, but Run:ai's AI-specific scheduler and fractionalization are often more sophisticated for deep learning workloads.
- Handling diverse and dynamic AI workloads: AI development involves various types of workloads, from interactive data exploration in notebooks to large-scale distributed training and inference serving. These workloads have different resource requirements and priorities. NVIDIA Run:ai's scheduler is designed to understand these nuances, allowing organizations to set policies, manage quotas and prioritize jobs automatically. This prevents resource contention and ensures that critical workloads get the resources they need, while research and development can still proceed efficiently.
- Simplifying infrastructure management for IT/MLOps teams: Managing a shared infrastructure of GPUs for multiple data science teams can be complex. Run:ai provides a centralized control plane and visibility dashboards that allow IT and MLOps teams to monitor resource usage, track workloads and enforce policies across on-premises, public cloud and hybrid cloud clusters.
- Enabling fair and governed resource access: In organizations with multiple teams, ensuring fair access to shared GPUs is a requirement. Run:ai's fair-share scheduling and quota management features allow administrators to define how resources are allocated among different teams or projects based on business priorities.
- Supporting hybrid and multicloud environments: Many enterprises operate in hybrid or multicloud environments. NVIDIA Run:ai is designed to pool resources from different locations into a unified platform, providing a single control plane for AI resources, regardless of where they are deployed. This flexibility is a key advantage for many organizations.
While many competitors offer pieces of the MLOps landscape, NVIDIA Run:ai's core strength is based on intelligent orchestration and optimization of the underlying compute infrastructure to maximize efficiency and accelerate the AI development lifecycle.