Partner POV | Unlocking AI Performance: Splunk Observability for Cisco Secure AI Factory with NVIDIA
In this article
This article was written by Derek Mitchell, Staff Observability Specialist at Splunk
Cisco AI PODs: The foundation for AI innovation
Cisco AI PODs are modular, flexible, and scalable AI infrastructure designed to accelerate time to value for AI projects. They allow organizations to deploy production-grade AI environments quickly—but to keep those environments running optimally, teams need comprehensive insight into performance and health.
How can you detect issues early, troubleshoot efficiently, and focus on delivering business outcomes instead of spending time addressing urgent production issues? That's where observability becomes indispensable.
Splunk Observability: Your eyes and ears inside AI PODs
Splunk Observability Cloud delivers end-to-end visibility across every layer of Cisco AI PODs—from physical infrastructure to Kubernetes to the AI applications layer.
It's not just about data collection. Splunk turns metrics, traces, and logs into actionable insights, helping teams detect, troubleshoot, and resolve issues in seconds.
We're excited to introduce a new Splunk Dashboard purpose-built for observability across the entire AI POD stack.
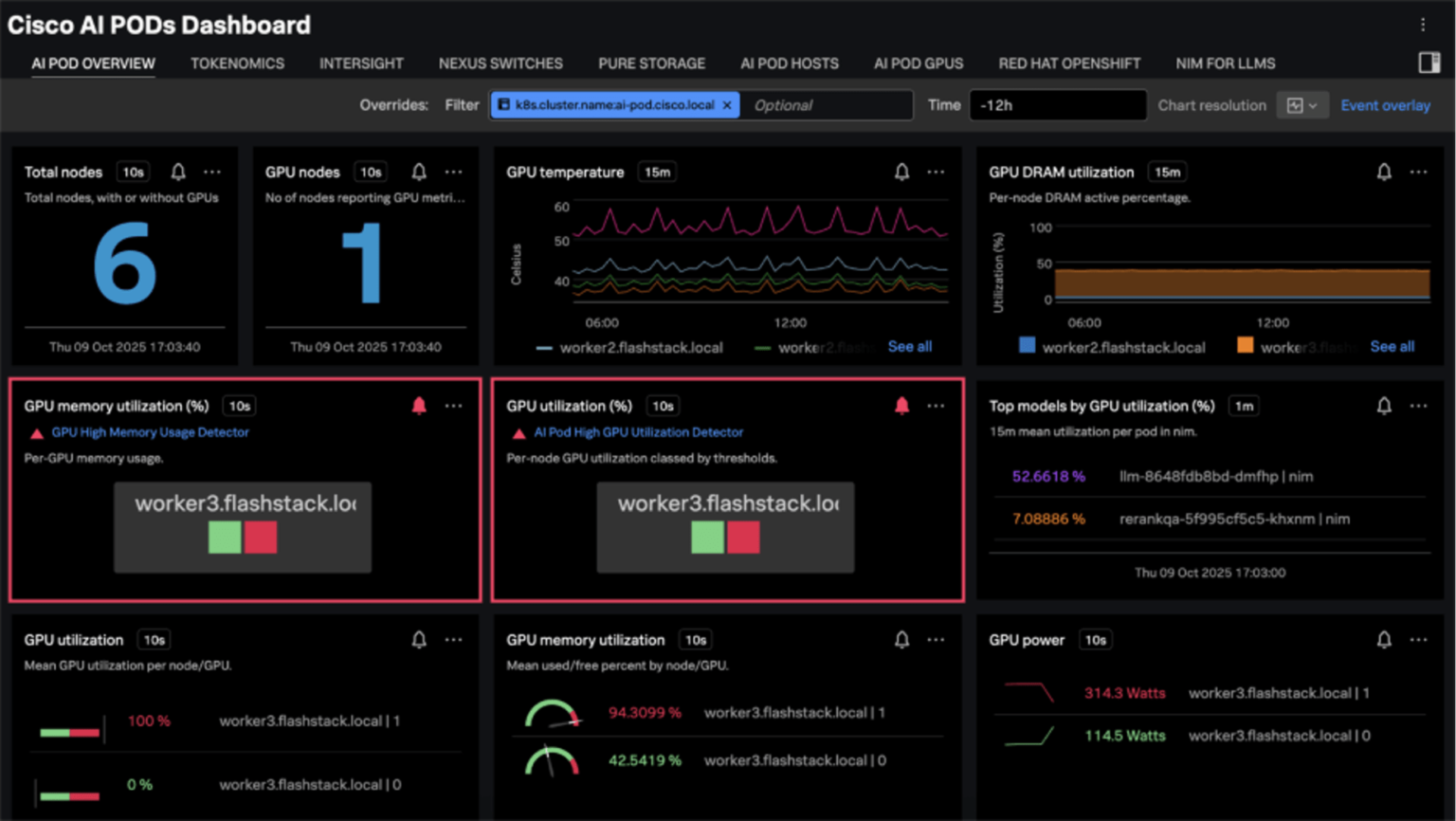
What the new Splunk Dashboard brings to Cisco AI PODs
- Unified Kubernetes cluster monitoring – Get a single view of all Kubernetes clusters, including Red Hat OpenShift running on AI PODs.
- Deep host-level insights – Monitor the performance of individual Cisco UCS servers, including CPU, memory, disk, and network utilization.
- AI POD infrastructure dashboard – Track critical metrics like GPU utilization, GPU memory usage, power, and network performance, integrating data from Cisco Intersight and Cisco Nexus.
- Streaming analytics advantage – Leverage Splunk's real-time streaming analytics to achieve faster detection and near-instant "time to glass."
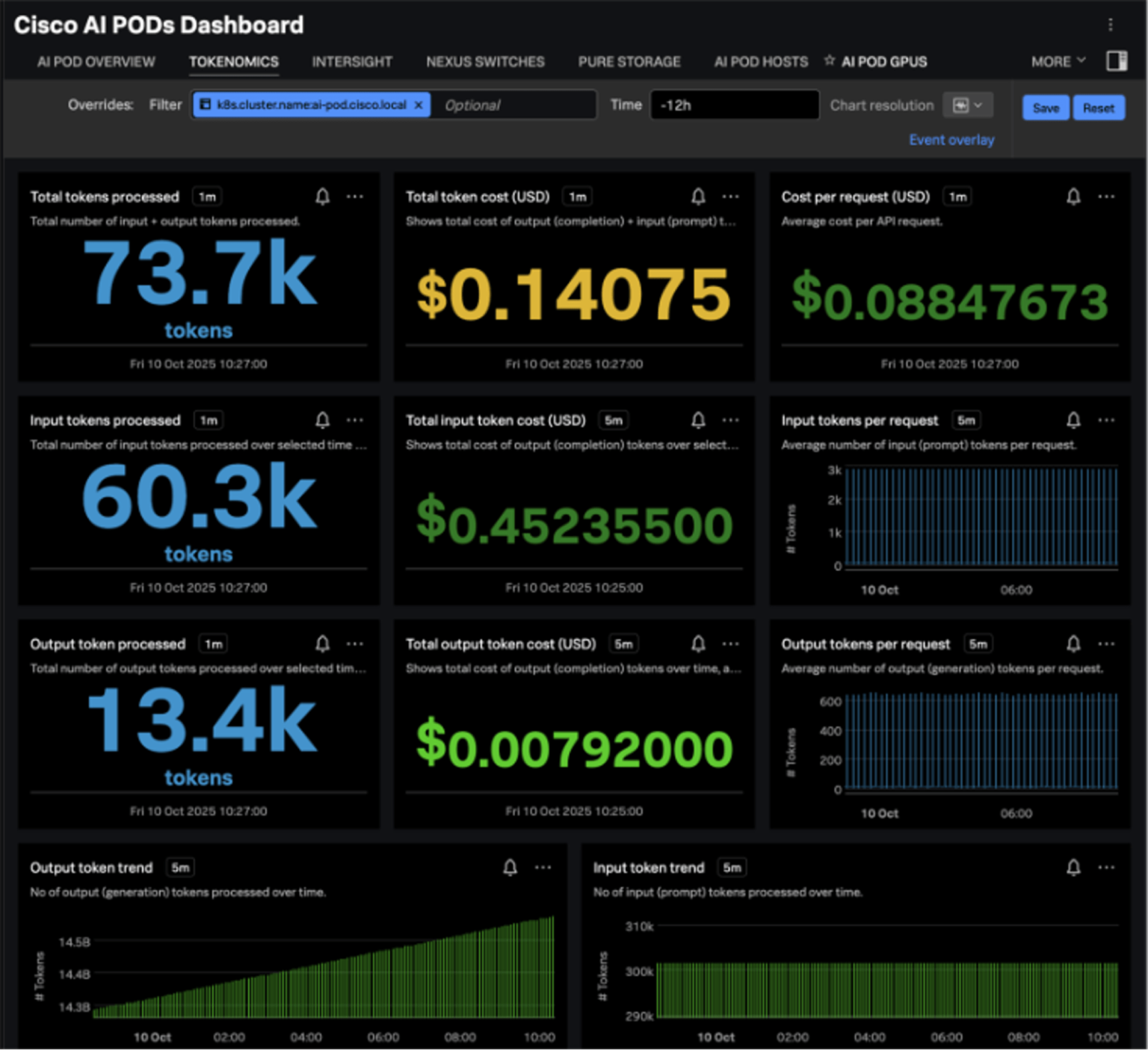
While Cisco AI PODs provide modular, scalable infrastructure for enterprise AI, each AI POD can also be monitored individually. This allows teams to gain detailed insight into the unique performance metrics and workloads of a specific deployment. Here are some screens from the Splunk Dashboard for AI PODs to help visualize the monitoring capabilities. By aggregating the number of input and output tokens processed by the large language model (LLM) running on an AI POD, Splunk is able to calculate an approximate cost for token usage over time:
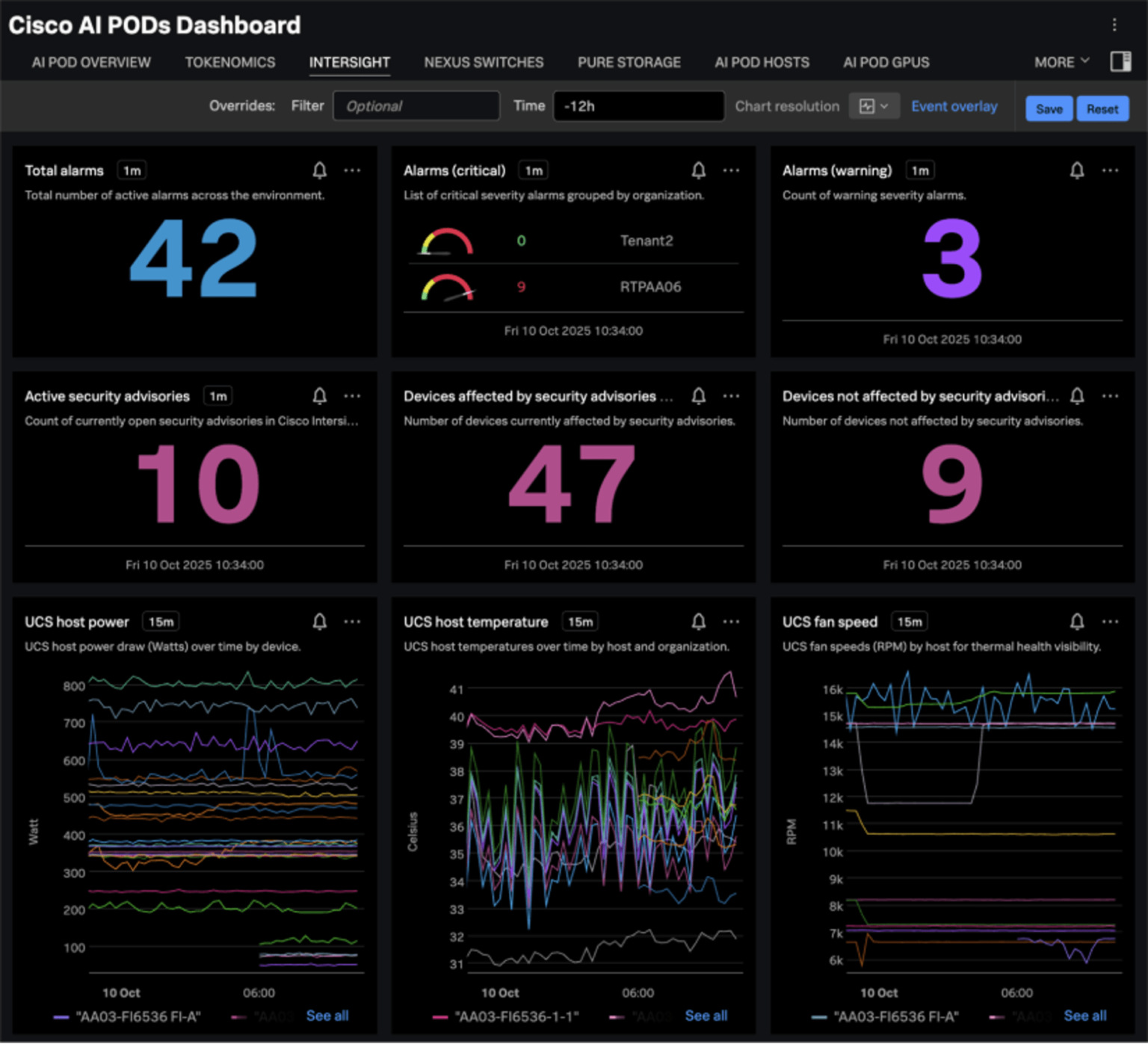
Splunk also pulls in metrics from Cisco Intersight, to provide visibility to active alarms related to the monitored AI POD, and key UCS metrics such as UCS host power, temperature, and fan speed:
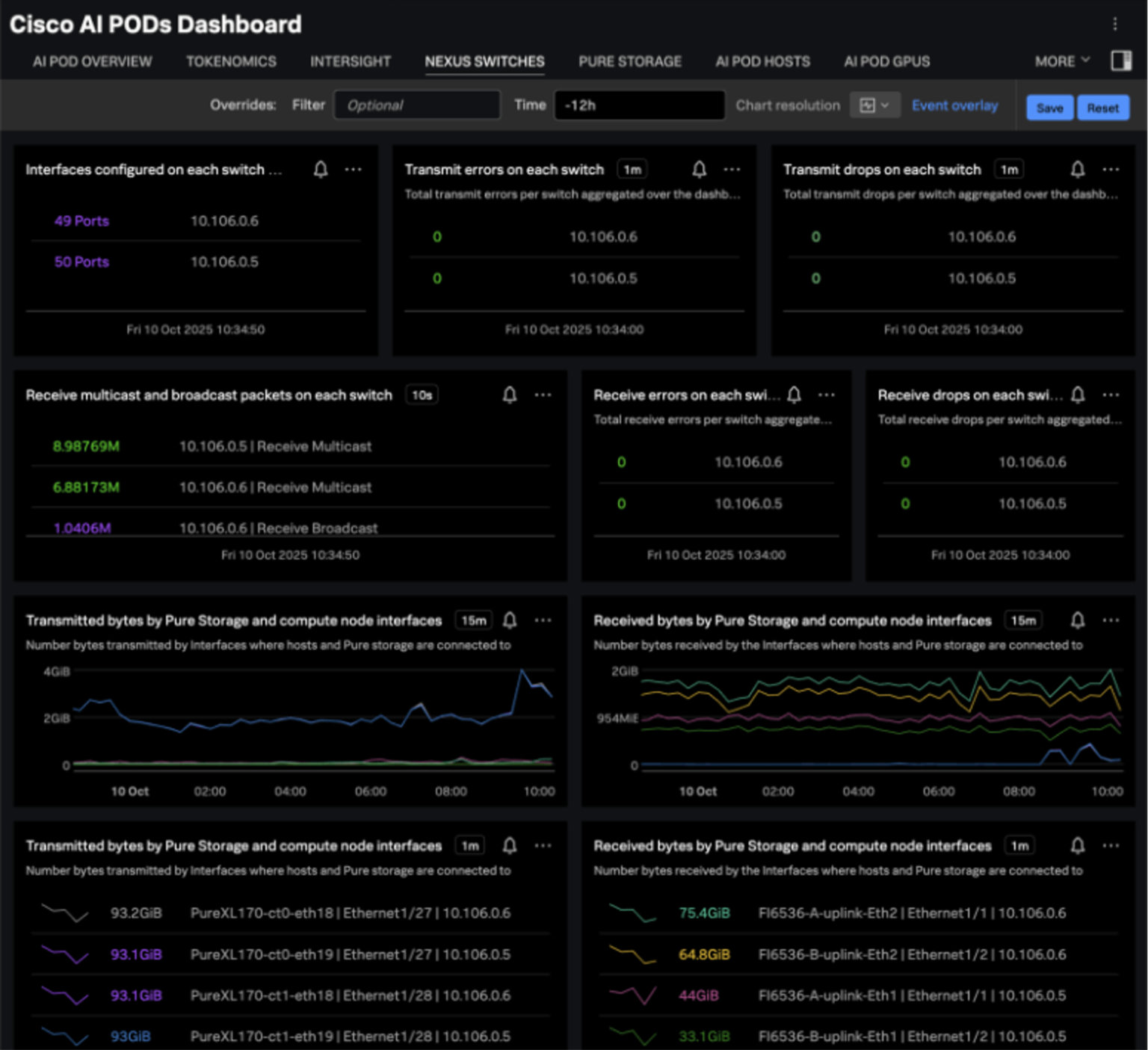
The Nexus dashboard provides insight into the interfaces configured on each Nexus switch, the transmit errors and drops, and the data transferred between storage and compute nodes:
A real-world scenario: Diagnosing LLM latency
Imagine an application running on a Cisco AI POD utilizing an LLM for user queries. Suddenly, response times on the application spike. Here's how Splunk Observability Cloud helps resolve it in minutes:
- Alert triggered – Splunk detects high response times and raises an alert.
- Trace analysis – The service map highlights that most latency occurs within /v1/chat/completions calls to the LLM.
- Infrastructure view – The AI POD dashboard shows that only one of the four available GPUs is active and fully utilized.
- Actionable insight – You reconfigure the workload to use all GPUs—instantly restoring performance.
The NVIDIA connection: Powering intelligent workloads
Splunk Observability also monitors key NVIDIA AI Enterprise components—including the NVIDIA NIM operator and NVIDIA NIMs microservices for LLM inferencing—ensuring the NVIDIA software stack performs at its best.
FedRAMP and government readiness: Splunk's current path towards achieving FedRAMP Moderate for Splunk Observability
Splunk remains a trusted partner in government digital transformation, empowering agencies to deliver secure, resilient, and intelligent services through cloud and customer-managed solutions. Building on the success of Splunk Cloud Platform—authorized at FedRAMP High and DoD Impact Level 5, and listed on the StateRAMP (dba GovRAMP) Authorized Products List—Splunk continues to invest in expanding our FedRAMP program to meet evolving public sector needs. As previously announced, Splunk Observability Cloud has already received "In Process" designation and awaits full authorization to operate at the Moderate level from the FedRAMP Program Management Office. Splunk remains committed to supporting the security and mission success of all our government customers.
Observability: A cornerstone of Cisco Secure AI Factory with NVIDIA
In Cisco Secure AI Factory with NVIDIA, observability is not optional—it's foundational.
By delivering deep, real-time insights across infrastructure and applications, Splunk Observability Cloud enhances:
- Operational efficiency
- Resource optimization
- Reliability and uptime
- Security posture
This holistic visibility is essential for building, operating, and securing complex AI pipelines at scale.
Conclusion
Cisco AI PODs deliver the robust, scalable infrastructure required for today's demanding AI workloads. When paired with Splunk Observability Cloud, organizations gain unmatched visibility and control—enabling rapid troubleshooting, optimal performance, and faster innovation.
Splunk Observability forms a core pillar of Cisco Secure AI Factory with NVIDIA, empowering businesses to build and run AI with confidence, speed, and security.