The NVIDIA–Cisco Spectrum-X Partnership: A Technical Deep Dive
A Two-Phase Integration for AI/ML Networking
In a significant development for AI and high-performance networking, NVIDIA and Cisco have announced a two-phase strategic integration focused on bringing the strengths of Cisco's networking hardware and operating systems into the NVIDIA Spectrum-X ecosystem. The partnership is designed to align the industry's most advanced Ethernet solutions with the requirements of AI/ML workloads—where deterministic latency and scale matter more than ever.
- Phase 1 of the alliance allows Cisco silicon and software to interoperate with NVIDIA's BlueField and ConnectX-8 SuperNICs while actively participating in Adaptive Routing (AR)
- Phase 2 pushes deeper: Cisco's NXOS network operating system will be running on NVIDIA Spectrum ASICs, allowing customers to unify operational paradigms between enterprise and AI fabrics on a Cisco switching platform.
This expanded partnership marks a fundamental shift in the AI networking landscape, enabling flexibility, scalability, and vendor interoperability at a time when AI/ML requirements are pushing fabric technologies to their limits.
Another benefit is that Cisco will be participating in NVIDIA Cloud Partner (NCP) and Enterprise Reference Architecture programs. This means Cisco will be able to publish validated designs and reference architectures incorporating NVIDIA Spectrum-X networking solutions.
For the original press release, click here
******************************************************************************************
Technical Refresh: Load Balancing in Ethernet Fabrics
While the alliance has some rather far-reaching implications in terms of customer choice and integrated solutions (eg, HyperFabric AI, covered later in this blog), the immediate technical implications are focused on how to build a better Ethernet fabric.
Classic Ethernet Load Balancing
Traditional Ethernet fabrics rely on Equal-Cost Multipath (ECMP) routing based on 5-tuple hashing (source/destination IP, source/destination port, and protocol). This ensures in-order packet delivery for each flow while minimizing the complexity at endpoints. However, this model struggles under AI/ML workloads for several reasons:
- Large flows dominate available bandwidth.
- The entropy of the hash is insufficient to distribute traffic across all possible paths.
- Overloaded paths are not detected or avoided until it's too late.
In short, while classic ECMP provides order, it lacks adaptability and reliability—a critical flaw when training jobs must scale across thousands of GPUs.
Cisco's DLB & Flowlet-Based ECMP
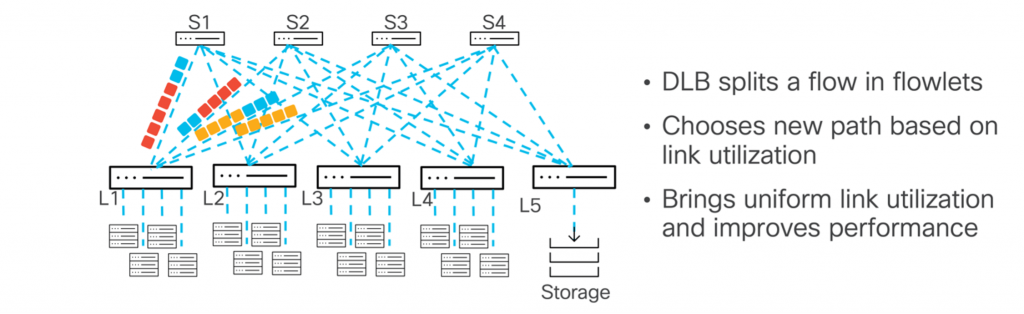
Cisco's approach leverages DLB (Dynamic Load Balancing) to identify microbursts of packets within a flow (called flowlets) based on inter-packet gaps. These flowlets can be sprayed independently across multiple ECMP paths without causing packet reordering, as long as they are sufficiently separated in time.
- This technique operates entirely within the network, requiring no changes at endpoints.
- It increases entropy and helps alleviate hot-spots by distributing traffic across more paths dynamically.
This approach gives Cisco a method that is AI-friendly while preserving traditional network layering. DLB can also be configured to perform per-packet spraying across the fabric, but this will place the onus of packet ordering on the receiving host.
NVIDIA's Adaptive Routing with NIC-Level Reordering
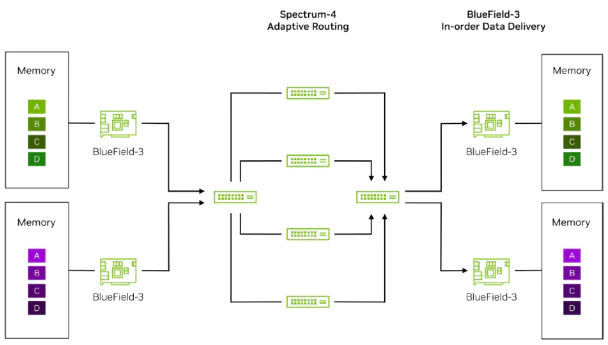
NVIDIA's approach uses packet-level spraying with end-to-end orchestration between SuperNICs and the network:
- Adaptive Routing (AR) dynamically selects the least-congested next hop on a per-hop basis using real-time telemetry and congestion awareness of next-hop neighbors. This function is entirely in the network fabric.
- Congestion Notifications are sent from targets to initiators. Those initiators will then take a metering approach to ensure fair access to bandwidth.
- At the receiving end, BlueField SuperNICs reorder packets without any extra load on the endpoint processors, eliminating the traditional need to keep flows ordered within the network.
This is part of NVIDIA's SpectrumX solution. This method radically boosts fabric utilization and throughput, especially for AI/ML training where latency predictability and load spreading are more important than strict in-order delivery.
For an in-depth exploration of this topic, please refer to Eric Fairfield's article on ECMP
******************************************************************************************
Implementation: Phase-by-Phase Changes
These are the specific technical updates we can expect to see as the expanded partnership takes shape.
Phase 1: Enabling NXOS for NVIDIA AR
NVIDIA Side:
- A software-based compatibility update will allow Cisco switches to interoperate with NVIDIA's SuperNICs and participate in AR at an Ethernet fabric level
Cisco Side:
- Update NXOS to:
- Enable per-packet egress queue utilization.
- Perform next-hop telemetry exchange, where each switch shares a local congestion score with neighbors.
- Construct an eligibility metric that guides packet forwarding decisions, coordinated with endpoints.
- The Cisco switches will also need to be enabled to recognize traffic marked by SuperNICs as AR-eligible
- This will be available on CloudScale and SiliconOne ASICs
- This is scheduled for NXOS 10(6).1
This creates a hybrid fabric where Cisco hardware and NVIDIA endpoints operate with shared awareness and real-time path adaptability.
Phase 2: NXOS on NVIDIA Spectrum
NXOS Integration:
- NXOS must be adapted to work with the NVIDIA Spectrum SDK, enabling native support for NVIDIA's ASICs.
- Currently under development, possibly on a next-generation ASIC beyond Spectrum-4.
Control Plane Enhancements:
- Features developed in Phase 1 will need to be brought forward into the new NXOS-on-Spectrum platform.
- The above enhancements will likely be a major release update rather than a new code train.
This phase represents full-stack unification—where Cisco software and NVIDIA hardware can be mixed or matched without losing adaptive networking features.
******************************************************************************************
Strategic Benefits
In short, who wins?
For Customers
- Interoperability & Choice: Customers gain flexibility in designing AI/ML fabrics with best-of-breed components from Cisco and NVIDIA.
- Consistent OS Experience: NXOS can serve as a unified control plane for both enterprise data centers and AI fabrics.
- Avoid Vendor Lock-In: Enterprises can maintain familiar tooling and operational models even as they scale into specialized workloads like AI.
- Reference Architecture: Customers will have NVIDIA-accepted reference architectures based on both NVIDIA and Cisco Ethernet solutions.
For Cisco
- Expanded Role in AI/ML: Previously sidelined in AI clusters dominated by NVIDIA's native networking, Cisco now embeds itself in those environments.
- Reference Architecture Visibility: Cisco hardware becomes eligible for inclusion in NVIDIA's validated blueprints, Reference Architectures, and go-to-market strategies via the NCP program.
- ASIC Flexibility: Showcases the power and programmability of SiliconOne in non-traditional (non-enterprise) use cases.
For NVIDIA
- Scalability: NVIDIA benefits from Cisco's proven scale and supply chain to support massive cluster rollouts.
- Fabric Reach: Spectrum-X's reach extends beyond NVIDIA-built clusters, making it easier for customers to deploy mixed environments.
- Resource Efficiency: Leveraging Cisco's expertise in security and operations for enterprise data centers enables NVIDIA to focus on its ASIC and silicon investments where it matters most.
******************************************************************************************
Cisco HyperFabric AI
Cisco's HyperFabric-AI (HF-AI) represents a tangible application of this alliance. It is a vertically integrated solution designed to unify compute, networking, storage, and telemetry into a single AI-optimized infrastructure platform.
Key architectural components include:
- UCS C885-Series compute nodes with high-bandwidth, GPU-optimized designs.
- Nexus 6000-Series with SiliconOne ASICs. These switches provide high radix and low-latency switching for AI workloads, leveraging telemetry and congestion-awareness options to DLB and AR techniques explored in the Spectrum-X collaboration.
- VAST Data's disaggregated, all-flash Universal Storage to deliver high-throughput, low-latency data access optimized for AI training pipelines and large-scale inference workloads.
- AI-Native Topologies: HF-AI supports non-blocking topologies such as folded CLOS and Dragonfly+ to optimize east-west traffic patterns common in AI/ML workloads.
- Intersight AI Operations: Integrated with real-time streaming telemetry from the fabric and compute nodes, this allows dynamic workload placement and congestion mitigation, guided by intent-based policy.
- Note: HF-Ai will include both NVIDIA Adaptive Routing and DLB options
HyperFabric-AI provides a turnkey, operationally simplified, and highly scalable solution for customers that allows them to embrace best-of-breed technologies from Cisco, NVIDIA, and VAST.
******************************************************************************************
Conclusion
The NVIDIA–Cisco Spectrum-X partnership represents a forward-looking alliance that directly addresses some of the most pressing challenges in AI/ML networking. By combining NVIDIA's adaptive, telemetry-driven approach with Cisco's scalable silicon and network operating system, the two companies are creating a flexible, high-performance Ethernet fabric for the AI era. In doing so, they are not only redefining load balancing and congestion control—but also blurring the lines between enterprise and HPC networking, giving customers a true multi-vendor, best-in-class ecosystem.
What's Next?
As Cisco and NVIDIA's #1 partner, WWT is working closely to understand AI/ML infrastructure innovations before they come to market. In keeping with that, WWT's unique AI Proving Ground (AIPG) provides customers and partners alike with the opportunity to examine technologies not only on their own, but also their performance when integrated into heterogenous network, storage, and compute ecosystems.
Future testing within the AIPG will evaluate HF-AI alongside Spectrum-X for performance, manageability, and scalability comparisons. Stay tuned here for updates.